




In an era where data is as valuable as currency, many industries are faced with the challenge of sharing and enriching data between different entities without violating privacy norms. Generating synthetic data allows organizations to bypass privacy hurdles and unlock the potential for collaborative innovation. This is particularly relevant for distributed systems where data is not centralized and is spread across multiple locations, each with their own privacy and security protocols.
Introduced by researchers from Delft University of Technology, BlueGen.ai, and University of Neuchâtel silofuse We are exploring ways to seamlessly generate synthetic data in a fragmented landscape. Unlike traditional techniques that struggle with distributed datasets, SiloFuse introduces a breakthrough framework that synthesizes high-quality tabular data from siled sources without compromising privacy. The method leverages a distributed latent tabular diffusion architecture and cleverly combines autoencoders and stacked training paradigms to avoid the complexities of cross-silo data synthesis.

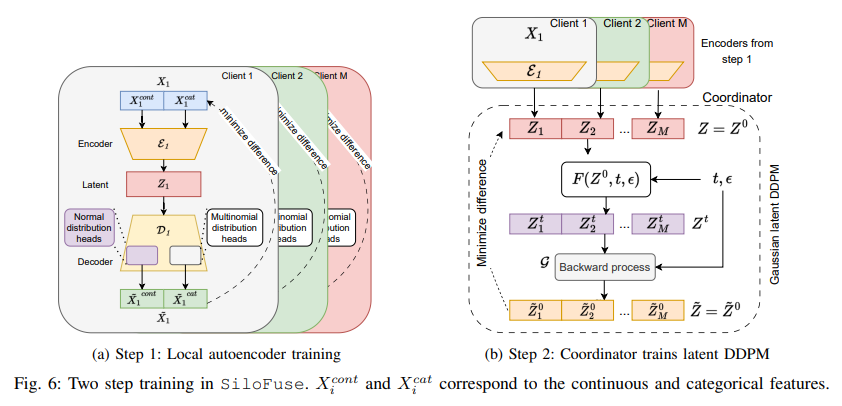
SiloFuse employs a technique in which the autoencoder learns the latent representation of each client's data, effectively masking the true values. This ensures that sensitive data remains on-premises and protects your privacy. A big advantage of SiloFuse is communication efficiency. The framework leverages stacked training to significantly reduce the need for frequent data exchange between clients, minimizing the communication overhead typically associated with distributed data processing. Experimental results prove the effectiveness of his SiloFuse, showing its ability to significantly outperform centralized synthesizers in terms of data similarity and usefulness. For example, SiloFuse achieved up to 43.8% higher similarity scores and 29.8% higher utility scores than traditional generative adversarial networks (GANs) across a variety of datasets.


SiloFuse addresses the biggest privacy concern in synthetic data generation. The framework's architecture ensures that it is virtually impossible to reconstruct the original data from synthetic samples, providing robust privacy guarantees. Through extensive testing, including attacks designed to quantify privacy risks, SiloFuse has demonstrated superior performance, reinforcing its position as a secure method for synthetic data generation in distributed settings.
Research snapshot


In conclusion, SiloFuse addresses critical challenges in synthetic data generation within distributed systems and provides a breakthrough solution that bridges the gap between data privacy and utility. SiloFuse deftly integrates distributed latent tabular diffusion with autoencoders and stacked training approaches to go beyond traditional efficiency and data fidelity techniques and establish a new standard in privacy protection. The application's notable achievements, highlighted by significant improvements in similarity and usefulness scores, along with robust protection against data reconstruction, demonstrate SiloFuse's potential to redefine collaborative data analysis in privacy-sensitive environments. is emphasized.
Please check paper. All credit for this study goes to the researchers of this project.Don't forget to follow us twitter.Please join us telegram channel, Discord channeland linkedin groupsHmm.
If you like what we do, you'll love Newsletter..
Don't forget to join us 39,000+ ML subreddits


Hello, my name is Adnan Hassan. I'm a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at Indian Institute of Technology Kharagpur. I'm passionate about technology and want to create new products that make a difference.