


In a recent LinkedIn post, Google analyst Gary Illyes commemorated the 30th anniversary of robots.txt files by explaining a lesser known aspect of them.
A component of web crawling and indexing, the robots.txt file has been central to SEO practice since its introduction.
This is one of the reasons why it is still useful.
Robust Error Handling
Illies emphasized the files' error-resistance.
“Robots.txt is virtually error-free” Ilies said.
He explained in the post that the robots.txt parser is designed to ignore most mistakes without compromising functionality.
This means that if you accidentally include irrelevant content or misspell a directive, your file will still work.
He elaborated that parsers typically recognize and process key directives such as user-agent, allow, and disallow, but ignore content that they don't recognize.
Unexpected feature: Line command
Ilish pointed out the presence of line comments in the robots.txt file, but said the feature was puzzling given the error-tolerant nature of the file.
He invited the SEO community to speculate on the reasoning behind this addition.
Responses to Ilies' post
The SEO community's response to Illyes' post provides additional background information about the practical implications of robots.txt error tolerance and the use of line comments.
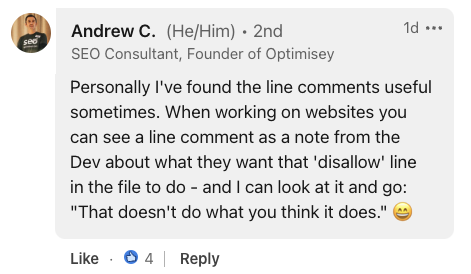
Andrew C., founder of Optimisey, emphasized the usefulness of line comments in internal communications, saying:
“When you're working on a website, you can see line comments in the files where the developer has noted what they want the 'disallow' lines to do.”
 Screenshot from LinkedIn, July 2024.
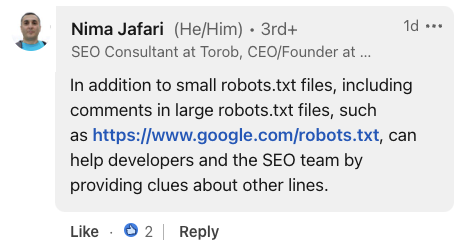
Screenshot from LinkedIn, July 2024.SEO consultant Nima Jafari highlighted the value of comments in large-scale implementations.
He noted that in the case of huge robots.txt files, comments can be “helpful to developers and SEO teams by providing clues about other lines.”
 Screenshot from LinkedIn, July 2024.
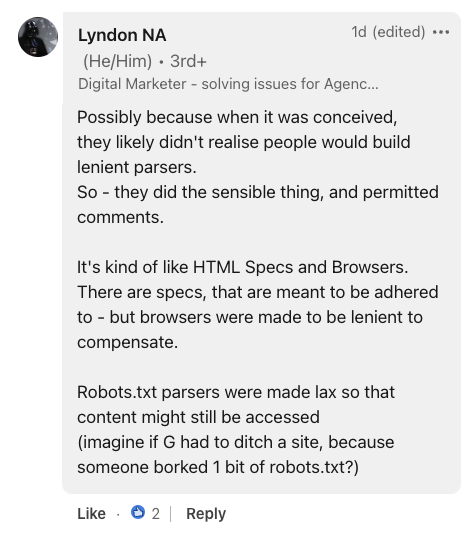
Screenshot from LinkedIn, July 2024.Digital marketer Lyndon NA provided some historical context and compared robots.txt to the HTML specification and browsers.
He suggests that the file's error tolerance is probably a deliberate design choice, stating:
“The robots.txt parser is loosely written, so content may be accessible (imagine what would happen if G had to abandon the site because someone broke one bit of robots.txt).”
 Screenshot from LinkedIn, July 2024.
Screenshot from LinkedIn, July 2024.Why is SEJ interested?
Understanding the nuances of robots.txt files will help you better optimize your site.
While file error resilience is generally beneficial, problems can slip through the cracks if not carefully managed.
What to do with this information
- Check your robots.txt file: Ensures that only the required directives are included and that there are no potential errors or misconfigurations.
- Be careful with your spelling: Parsers may ignore spelling mistakes, but this may result in unintended crawling behavior.
- Use line comments: Comments can be used to document your robots.txt file for future reference.
Featured image: sutadism/Shutterstock