




Large-scale language models (LLMs) such as GPT-4, Gemini, and Llama-2 are at the forefront of profound changes in the data annotation process, offering a blend of automation, accuracy, and adaptability that was previously unattainable manually. Offers. Traditional approaches to data annotation, the elaborate process of labeling data and training models, are time- and resource-intensive. LLM has advanced features that can revolutionize this important but tedious task.
The core problem with traditional data annotation is that it requires significant human effort and domain-specific knowledge, making the process expensive and time-consuming. The advent of LLM provides a solution by automating the generation of annotations, not only speeding up the process but also improving the consistency and quality of labeled data. This change is not just about efficiency. This is a fundamental change in the way data is prepared for machine learning applications. This ensures that models are trained on accurately annotated datasets that reflect complex nuances and context.
Researchers from Arizona State University, University of Virginia, ByteDance Research, and University of Illinois at Chicago published a study on the role of LLM in data annotation. The methodology of leveraging LLM for data annotation extends beyond simple automation. This includes advanced strategies such as rapid engineering and fine-tuning for specific tasks and domains. These LLMs are adept at understanding and generating nuanced and context-relevant annotations across a variety of data types. For example, by employing carefully designed prompts, LLM can create annotations that capture complex details, relationships, and classifications in the data, greatly reducing the manual workload and subjectivity associated with traditional annotation methods. can.

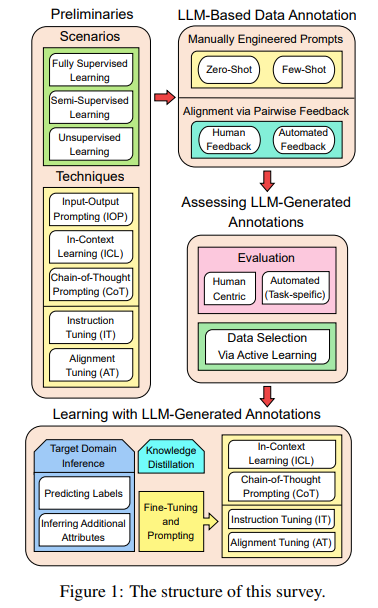
The performance and results obtained by using LLM in data annotation highlight its transformative impact. These models streamline the annotation process and deliver accuracy that sets new benchmarks in the field. The automatic annotation produced by LLM increases the consistency of the data labeling process and reduces the variability and errors inherent in manual annotation. This breakthrough in efficiency and accuracy opens new possibilities for machine learning applications, from improved model training to increased interpretability and reliability of machine learning output.
In conclusion, integrating LLM into data annotation allows you to:
- LLMs like GPT-4 automate and improve the data annotation process and go beyond traditional limitations.
- These models adapt to different data types through advanced prompt engineering and fine-tuning to provide high-quality annotations.
- The efficiency and accuracy of LLM in annotation generation is expected to improve the standards for training machine learning models.
- Employing LLM for data annotation streamlines the process and introduces a level of accuracy and consistency that was previously unattainable.
This study of the role of LLM in data annotation highlights its potential to revolutionize the field and fosters ongoing research and innovation. As these models evolve, the ability to automate and enhance data annotation will be critical to advances in machine learning and natural language processing technology.
Please check paper. All credit for this research goes to the researchers of this project.Don't forget to follow us twitter and google news.participate 38,000+ ML SubReddits, 41,000+ Facebook communities, Discord channeland LinkedIn groupsHmm.
If you like what we do, you'll love Newsletter..
Don't forget to join us telegram channel
You may also like Free AI courses….


Hello, my name is Adnan Hassan. I am a consulting intern at Marktechpost and will soon be a management trainee at American Express. I am currently pursuing a dual degree at Indian Institute of Technology Kharagpur. I'm passionate about technology and want to create new products that make a difference.