


The new buzzword in SEO is information acquisition. And like all new buzzwords, SEO is throwing it around like it's on fire.
But there's a big problem.
Obtaining information means different things to different people.
In this article, you will learn about acquiring information and how to use it to your advantage.
Three schools of information acquisition: humans, machines, and search engines
Retrieval of information is available for three topics:
- Machine learning.
- Google patent.
- Information gathering theory.
Information gains are used in machine learning to train decision trees. And unless you're a computer programmer, you can safely leave the can of worms largely unopened (for now).
When SEOs talk about acquiring information, they primarily refer to Google's patents.
Google was granted a patent in 2022 for information capture scores applied to documents.
The patent showed that Google has developed a way to measure the “sameness” of content and promote or demote it accordingly.
This is a great way for Google to deal with content that is not original in nature, or that has simply been copied and rephrased from another source.
But what about information acquisition in relation to information gathering theory?
Information Gathering Theory is documented in the book of the same name written by Peter Pirolli.
It applies a model of how animals look for food (optimal foraging theory) to how humans look for information (more on this later).
As you can see, the same term has three different meanings.
When it comes to SEO, Google's patents are mainly easy to understand and just make your content unique.
However, information gathering is more complex and requires more thorough investigation.
Why information gathering is important for SEO
Recently, Google started discussing information gathering theory in its Decoding Decision Report (messy middle).
In fact, information gathering theory seems to be the direction Google is heading, and to quote directly from that report:
“The explosion of product choices and information has made it difficult to have confidence in making the right decisions.”
In other words, there is too much information.
Too much information increases the time it takes to make a purchase decision, which is not good for anyone.
When you think about this, you can see why Google SGE is useful.
By providing generative AI responses to search queries, searchers can instantly understand the subject matter without having to click on a website.
This initial information helps users decide on their next search.
Get search results on Perplexity.
Within seconds, I had more knowledge about the best gym shoes for people with bad knees, and lots of links and suggestions.
The next click is to see the suggested shoes, not to read five more blog posts.
If SGE works the same way, we can see how commerce will fundamentally change.
We no longer optimize for Google. Optimized for AI.
Learn more: Optimizing LLM: Can you influence the output of your AI?
Get the daily newsletter search that marketers rely on.
From SEO to information acquisition optimization
Google has been involved in AI for a long time, and AI is part of many of its systems.
They used BERT to improve language understanding, but I think there are many more systems in use.
The important thing is that Google is trying to understand your content in order to better serve its search engine users. Therefore, Google itself is reading your content.
Sure, they're not like humans, but they're reading it.
So, just like humans, it makes sense that Google would apply a similar approach to increasing the information we get from our content.
In essence, we become information optimisers.
As SEOs, our job is to continually increase our information acquisition rates.
Gain rate explanation
In terms of information gathering theory, information acquisition rate can be explained as follows.
- Gain rate = value of information / cost associated with obtaining that information
As we know, search engines have a cost to index and retrieve documents, but so do humans.
When we use our minds, we burn calories, and our bodies work very efficiently to avoid wasting calories.
We use heuristics (mental shortcuts) to filter the world and make decisions.
Information gathering theory suggests that we are trying to do the same thing. We try to get as much information from a source as possible in the shortest possible time.
To do this, we go through a five-step process.
goal
- What information do you need?
patch
- We decide which sources of information are best suited to achieve our goals. This means going to TripAdvisor, TikTok, YouTube, or any website or search engine you can think of.
feed
- Here you will find the information you need on your chosen platform. This example uses Google. Enter keywords in a search engine to try to find the information you need.
scent
- When we head to a search engine, we're looking for a whiff of good sources. Signals such as reviews, top rankings, and page titles that encourage clicks.
- We decide whether to spend time clicking on sites, scanning information, and reading resources.
diet
- We gather information from multiple sources before making decisions. This is what Google calls the messy middle of search.
- For brands and sites, being part of a consumer's information diet makes them more likely to rely on and trust you for information.
As you know, that trust leads to more purchases and clicks (which can lead to advertising and affiliate revenue). This means that SEO must include optimization around information scent.
But if you've read the above, you'll know that Google search works just as well, but it's just the machine version.
Information optimization: the new science
When optimizing around information acquisition, you need to understand that you need a deeper understanding of two factors:
- Machine learning.
- human learning.
We already know that Google wants original, empirical information from the best sources.
We also want to reduce the cost of extracting that information.
Yes, Google wants an easy life. So how do we do this on a practical level?
Simply put, it makes information extraction easier for both machines and humans (at the same time). Here's how:
The best websites maximize the value of each interaction
Contrary to what many people think, while a fast website may be important, users will turn away if their information acquisition rate is low or the cost is perceived as high.
Here is an example.
We asked ChatGPT for information on hotels in Paris. They will provide you with information in the best possible way.

It provides a lot of information that can be easily extracted with low cognitive cost. But how should websites deal with this?
TripAdvisor has an entire page for the hotel. Look at how we optimized one section for information capture rate.
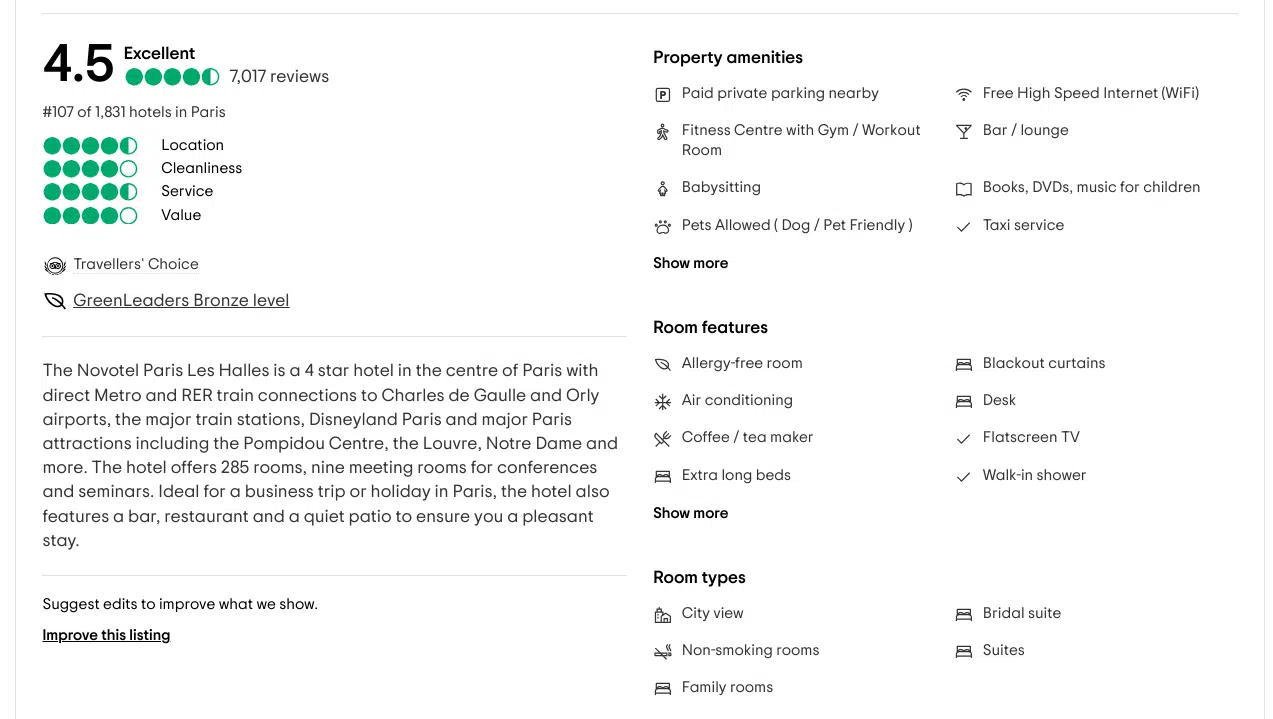
The content, which uses symbols, scorecards, and lists room types, is designed to help humans (and machines) obtain the most information in the least amount of time and cost.
And this is what we need to get our heads around to help search users.
But there are some myths that need to be busted around content.
Great content is based on context
I read a lot of good content, but most of it is in my inbox in the form of blogs written by people that aren't designed to get noticed in search.
SEO-friendly content varies widely.
When we search online, we enter a state of emotional need that requires a solution.
Kantar and Google did some research a while ago.

In this study, the above need states were used by searchers accessing search engines to solve them.
The words that stand out for each need condition are:
- quick.
- laser focus.
- specific phrases.
- To the point.
- Simplicity.
- simple.
- trust.
- evaluation.
- review.
- ability.
- position.
It is these attributes of information that searchers are looking for in online content.
It's amazing to see how TripAdvisor content displays these attributes, and how applying these attributes to content increases information retrieval rates for humans and machines. I understand.
But how do you get started with an information optimization approach to your content?
Well, here's a four-part process to get you started.
Part 1: Content structure
To increase your information capture rate, consider how your pages should be structured for search.
A good example is the Tui website.
We used a faceted search “button” to help users find what they're looking for.
Consider how best to design your pages for humans and search engines to increase information capture.
UX is just as important as the information on the page.
Part 2: Information architecture
Consider how to structure your information to get the most out of it.
For example, you may want to consider providing information early and quickly, such as:
“When is the best time to travel to Jamaica?”
“March is the best time to travel to Jamaica.”
Look at your content and aim to add some, if not all, of the following attributes:
- A quick adventure.
- laser focus.
- specific phrases.
- To the point.
- Simplicity.
- simple.
- trust.
- evaluation.
- review.
- ability.
Part 3: Content design
The final influence is the design of the content.
Consider how best to add value, such as using unique images in your posts to help illustrate information and data.
Backlinko uses images like the one above to convey data in an interesting format.
This brings us to the final part.
Part 4: Differences in content
If you do all of the above, you should end up with content that is very different from what you already have.
But if you don't, be sure to do so.
There are 1,000 different ways to say the same thing, which requires creativity and consideration as to how best to present your unique angle and perspective on this.
But here's a bit of a challenge.
Visit sites like Backlinko and HubSpot and look at their content.
Find an article, apply the four-part system above, and think about how you could improve it based on your own observations and experiences.
This could serve as a suitable workshop for agencies and in-house staff to consider the information gained and how best to use it.
Because in the age of generative content, information acquisition is paramount.
The opinions expressed in this article are those of the guest author and not necessarily those of Search Engine Land. Staff authors are listed here.