


Every day, physicians treat large numbers of patients with needs ranging from the simple to the highly complex. Providing effective care requires knowing each patient's health records and staying up to date on the latest procedures and treatments. And then there is the all-important doctor-patient relationship, which is built on empathy, trust, and communication. AI needs to be able to do all of these things if it is to come close to emulating real-world doctors.
The intersection of AI and healthcare is in full swing. In the past six months, New Atlas has shown how junior doctors can identify precursors to colon cancer, how images of the eye can diagnose childhood autism, and whether surgeons can remove all the cancerous tissue in breast cancer. We reported on an AI model that helps predict in real time whether Surgery. But Med-Gemini is something else.
Google's Gemini model is a new generation of multimodal AI models. This means that it can process information from different modalities, such as text, images, video, and audio. Models are proficient in language and conversation, understand the diverse information they are trained on, and perform so-called “long context inference” – inferences from large amounts of data, such as hours of video or tens of hours of audio. I understand.
Med-Gemini has all the benefits of the basic Gemini model, but with some tweaks. The researchers tested these medically focused adjustments and described their results in a paper. There's a lot going on in a 58-page paper. We have selected the most impressive parts.
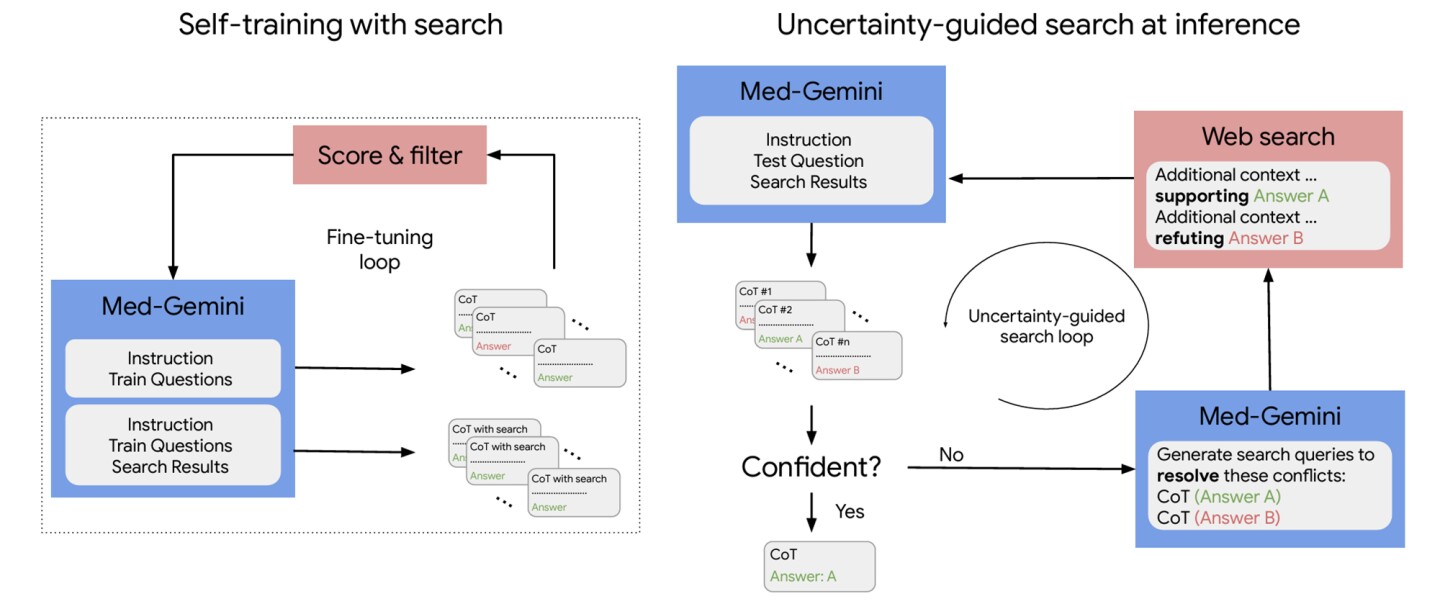
Self-training and web search capabilities
To arrive at a diagnosis and develop a treatment plan, physicians rely on their own medical knowledge and the patient's symptoms, medical history, surgical history, social history, laboratory and other investigational test results, and the patient's response. You need to combine it with a lot of other relevant information. Prior treatment. Treatments are “moving holidays” where existing treatments are updated or new treatments are introduced. All of these influence physicians' clinical reasoning.
That's why in Med-Gemini, Google has built in access to web-based search that enables more sophisticated clinical reasoning. Like many medicine-focused large-scale language models (LLMs), Med-Gemini can solve problems from the United States Medical Licensing Examination (USMLE) designed to test medical knowledge and reasoning across a variety of scenarios. I was trained on MedQA, which is a representative multiple-choice question.
Saab et al.
However, Google has also developed two new datasets for the model. The first, MedQA-R (Reasoning), extends MedQA with synthetically generated inference explanations called “Chain-of-Thoughts” (CoT). The second, MedQA-RS (Inference and Retrieval), provides instructions to the model to use web search results as additional context to improve answer accuracy. When a medical question yields an uncertain answer, the model is asked to perform a web search to obtain further information to resolve the uncertainty.
Med-Gemini was tested on 14 medical benchmarks, established new state-of-the-art (SoTA) performance on 10 medical benchmarks, and outperformed the GPT-4 model family on all comparable benchmarks. On the MedQA (USMLE) benchmark, Med-Gemini achieved 91.1% accuracy using an uncertainty-based search strategy, outperforming Google's previous medical LLM, Med-PaLM 2, by 4.5%.
About 7 multimodal benchmarks including: New England Medical Journal (NEJM) Image Challenge (images of difficult clinical cases where diagnosis is made from a list of 10), Med-Gemini outperformed GPT-4 with an average relative margin of 44.5%.
“While the results… are promising, further significant research is needed,” the researchers said. “For example, we do not intend to use multimodal search searches to limit search results to more reliable medical sources, or to perform analysis on the accuracy and relevance of search results and citation quality. Furthermore, we do not yet know whether small LLMs can be taught how to use Web search. We leave these explorations for future work.”
Retrieving specific information from long electronic medical records
Electronic health records (EHRs) can be long, but doctors need to be aware of what's in them. Complicating matters are typically text similarities (“diabetes” vs. “diabetic nephropathy”), misspellings, acronyms (“Rx” vs. “prescription”), and synonyms (“cerebrovascular accident”). vs. “stroke''). What could be a challenge for AI.
To test Med-Gemini's ability to understand and reason about long-context medical information, the researchers used the Intensive Care Medical Information Mart, a large publicly available database, and MIMIC-III. , contains anonymized health data of patients admitted to intensive care.
The goal of the model was to search a large collection of clinical notes in the EHR (the “haystack”) for relevant mentions of rare and subtle medical conditions, symptoms, or procedures (the “needle”).
Two hundred cases were selected, and each case consisted of a collection of anonymized EHR notes from 44 ICU patients with long medical histories. The following criteria were required.
- Over 100 medical notes. Each example ranges in length from 200,000 to 700,000 words.
- In each example, the condition is mentioned only once
- Each sample had one condition of interest
There were two steps to putting a needle in a haystack. First, Med-Gemini had to search its extensive records for all mentions of a particular medical problem. Second, the model had to evaluate the relevance of all mentions, classify them, conclude whether the patient had a history of the problem, and provide a clear basis for the decision.

Saab et al.
Compared to the SoTA method, Med-Gemini showed better performance on the needle-in-a-haystack task. It was rated 0.77 in precision compared to the SoTA method (0.85) and outperformed the SoTA method in recall (0.76 vs. 0.73).
“Perhaps the most notable aspect of Med-Gemini is its long-context processing capabilities, which open up new performance frontiers for medical AI systems and the possibility of novel applications not previously possible. ,” the researchers said. “This 'needle in a haystack' search task reflects a real-world challenge faced by clinicians, and Med-Gemini-M 1.5's performance demonstrates how to efficiently extract and analyze This information shows the potential to significantly reduce cognitive load and improve clinician performance.”
For an easy-to-understand explanation of these key research points, and the latest on the mudslinging between Google and Microsoft, watch the AI Explained video starting at 13:38.
New OpenAI models 'imminent' raises stakes in AI (plus Med Gemini, GPT 2 chatbots, Scale AI)
Conversation with Med Gemini
In a real-world usability test, Med-Gemini was asked by patient users about itchy skin lumps. After requesting an image, the model asked appropriate follow-up questions to accurately diagnose the rare lesion and recommend what the user should do next.

Saab et al.
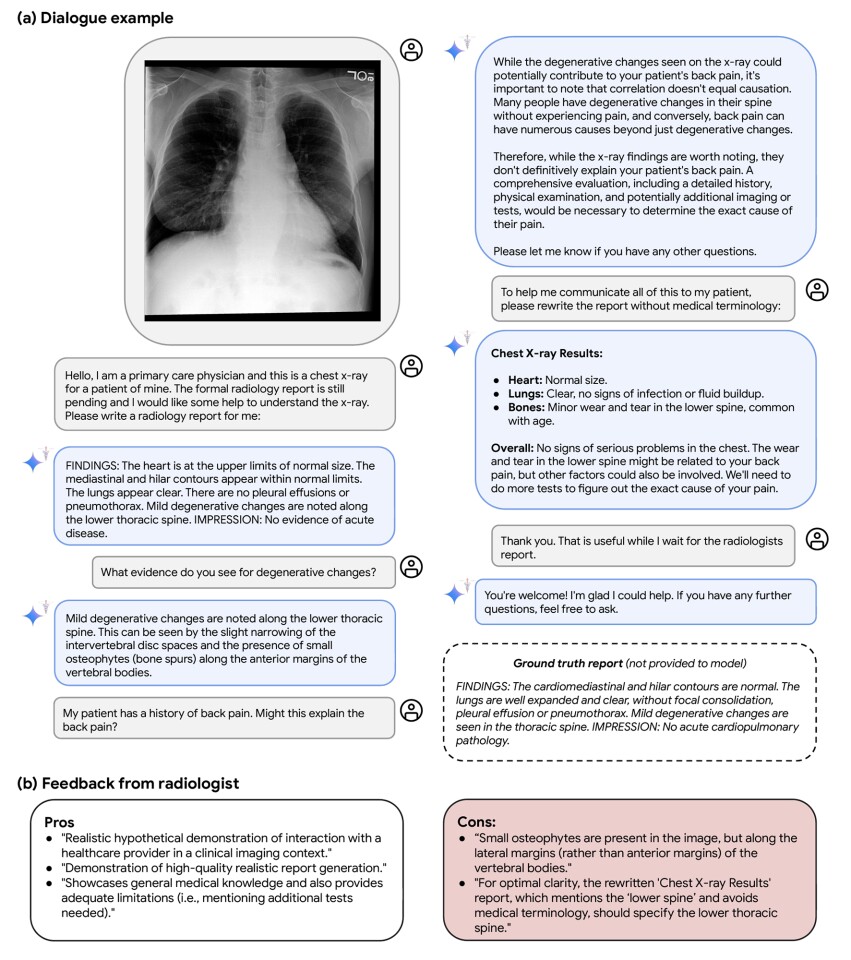
Med-Gemini was also asked to interpret chest X-rays for physicians and create a plain English version of the report that could be provided to patients while awaiting the official radiologist's report.
Saab et al.
“Med-Gemini-M 1.5's multimodal conversation capabilities are promising given that they can be achieved without any special fine-tuning of medical interactions,” the researchers said. “Such capabilities enable seamless and natural interactions between people, clinicians, and AI systems.”
However, researchers acknowledge that more research is needed.
“This capability has great potential for useful real-world applications, such as assisting clinicians and patients, but of course also comes with very significant risks,” they said. “While we highlight the potential for future research in this area, the functionality of clinical conversations in this study, as previously explored by others in specialized research towards conversational diagnostic AI, have not been rigorously benchmarked.
future vision
Where do we go from here? The researchers acknowledge that there is still much work to be done, but the initial features of the Med-Gemini model are certainly promising. Importantly, we plan to incorporate responsible AI principles, including privacy and fairness, throughout the model development process.
“Privacy considerations, in particular, need to be rooted in existing health care policies and regulations that govern and protect patient information,” the researchers said. “Fairness is also an area that requires attention. AI systems in healthcare can unintentionally reflect or amplify historical biases and inequities, leading to potentially heterogeneous model performance and It can have harmful consequences for marginalized groups.”
But ultimately, Med-Gemini is seen as a tool for good.
“Large-scale multimodal language models are ushering in a new era of possibilities in health and medicine,” the researchers said. “The capabilities demonstrated by Gemini and Med-Gemini signal significant advances in the depth and breadth of opportunities to accelerate biomedical discovery and support healthcare delivery and experience. It is of paramount importance that progress be accompanied by careful attention to the reliability and safety of these systems.Prioritizing both aspects will ensure that the capabilities of AI systems meaningfully advance both scientific progress and medical care. We can responsibly envision a future that promotes safety.”
The study can be accessed through the preprint website arXiv.