




Scaling up LLM poses significant challenges as it requires vast computational resources and high-quality datasets. The pre-training process typically involves taking a model with billions of parameters and training the model on a dataset containing trillions of tokens. This complex procedure requires considerable computational power and access to high-quality data to improve the performance of language comprehension and production tasks.
Researchers at UT Austin say,inheritance”, How to distinguish between small and large base LMs. They inherit some transformation blocks from a larger LM and train a small model on a small fraction (0.1%) of the original pre-training data. This approach leverages a single GPU to efficiently create an LM with 1.5 billion parameters in less than 12 hours using just 1 billion tokens. Despite using significantly less data, the resulting model performs on par with publicly available LMs trained on large datasets and demonstrates effectiveness across a variety of settings. .

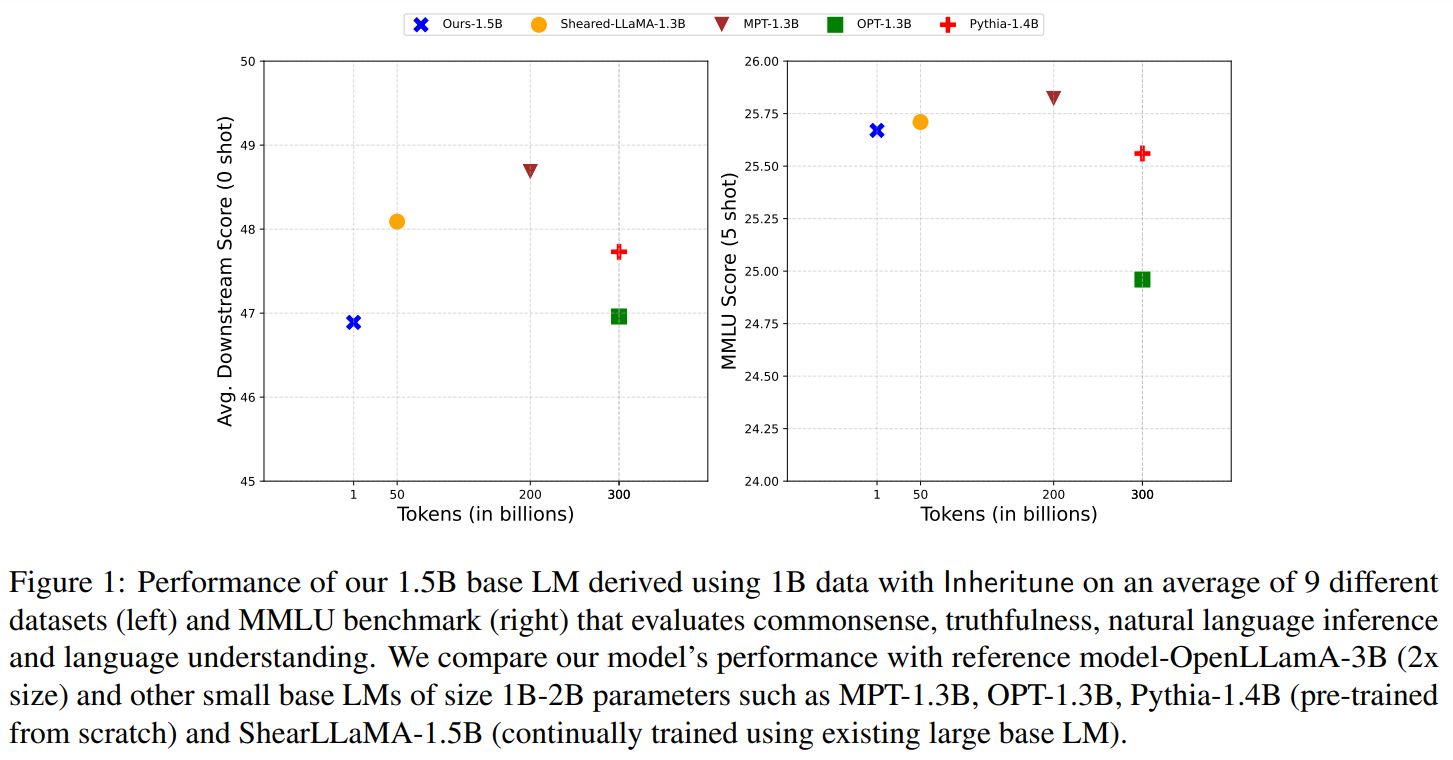
Previous approaches to training small-based LMs have included large-scale training from scratch with trillions of tokens or leveraging high-quality synthetic data. For example, tinyllama-1B is trained from scratch with 3 trillion tokens over 90 days. In contrast, Inheritune efficiently trains small base LMs by inheriting transformer blocks from larger models and training them on a small subset of data, achieving comparable performance with significantly fewer computational resources. will be achieved. While model compression techniques have been successful in other areas such as neural networks, they are still not very effective for the complex features of large-scale LMs.
In the Inheritune approach, a small base LM is created by inheriting some of the pre-training data and some layers from an existing larger LM. First, the first n layers of the referenced model are inherited and the target model is initialized. The target model is then trained on the available subset of training data for the specified number of epochs. In an experiment, the researchers used his 1 billion token subset of his Redpajama v1 dataset to train a 1.5 billion parameter LM and compared it to scratch-trained and derived LMs to achieve competitive performance. achieved a certain performance. Researchers have evaluated their approaches using different baseline models, mainly considering the quality of the pre-training data for a fair comparison.
Inheritance allows the extraction of smaller target LMs without sacrificing performance, resulting in comparable zero-shot performance on related downstream tasks. Additionally, these LMs outperform similarly sized models trained from scratch and outperform them with fewer training steps. Experiments with the GPT2 medium model demonstrate that initialization with Inheritune, especially the use of retention and MLP weights, provides good convergence speed and final validation loss performance. Surprisingly, initializing the attention or MLP weights similarly improves convergence speed and validation loss.
Additionally, limitations of the Inheritune method include the inability to change the architectural design other than by changing the number of transformer blocks, which can limit flexibility in customizing hidden sizes and attention heads. . Due to the small size of the training dataset, sensitivity to the quality of the training dataset is also an issue. Additionally, we need to explore ways to improve the selection of retained blocks, curation of datasets, and tuning of hyperparameters. Nevertheless, this study shows that Inheritune effectively pre-trains small base language models with minimal data and computational resources, providing a direct approach to model reduction from large reference models. Then I conclude.
Please check Paper and Github. All credit for this study goes to the researchers of this project.Don't forget to follow us twitter.Please join us telegram channel, Discord channeland linkedin groupsHmm.
If you like what we do, you'll love Newsletter..
Don't forget to join us 40,000+ ML subreddits
Learn more about content partnerships here Please fill out the form here.


Sana Hassan, a consulting intern at Marktechpost and a dual degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a new perspective to the intersection of AI and real-world solutions.