

More than a decade ago, Arm executives saw rising data center energy costs and expanded on the low-power architecture of the company's eponymous system-on-chip, which had dominated the mobile phone market since its inception. I felt an opportunity to do so. And it took over the embedded device market from PowerPC to enterprise servers.
The idea was to create a lower power, cheaper, and more adaptable alternative to Intel Xeon and AMD Epyc CPUs.
The architecture took years to develop, the disappointment of some of the early Arm server processor vendors going bankrupt or withdrawing from the program, and a huge effort to grow the software ecosystem. The company currently has a strong foothold in on-premises systems and the cloud.data center
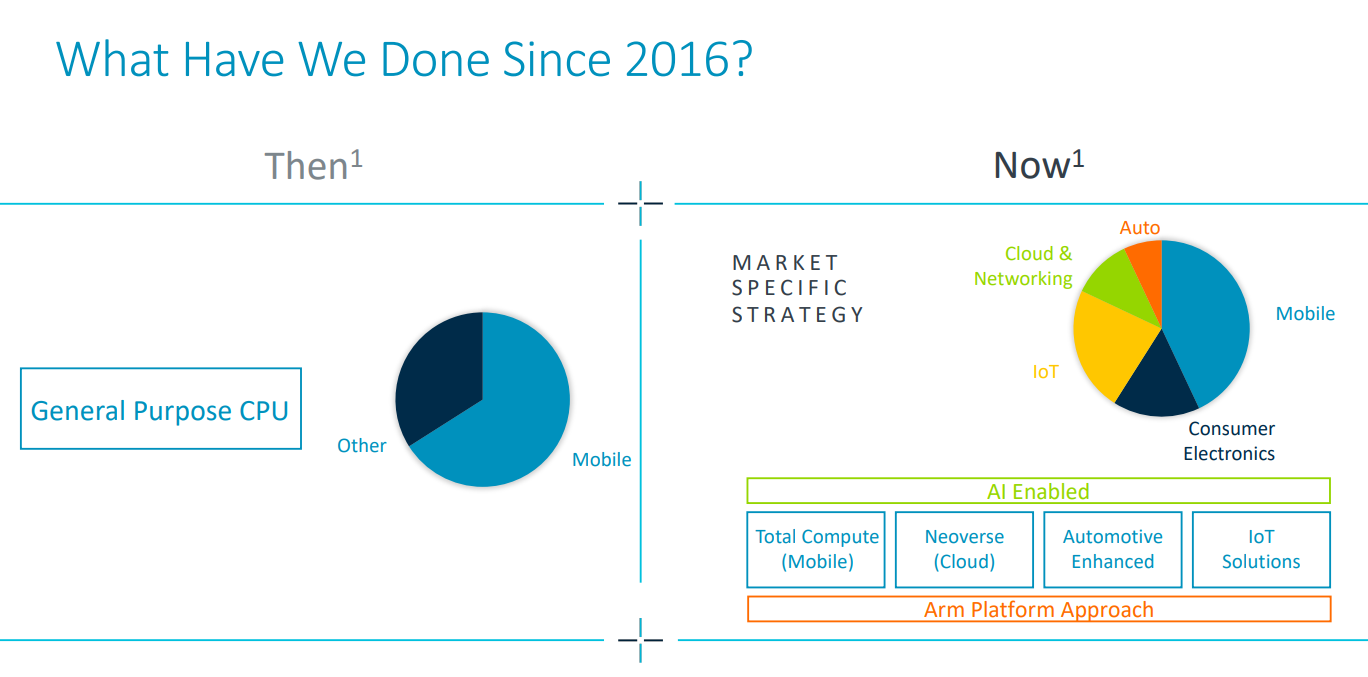
In its latest quarterly earnings report released in February, Arm boasted of its platform approach to the market, noting that at least two-thirds of its 2016 revenue came from general-purpose CPUs in the mobile space. Platforms are now available for multiple markets, including cloud and networking systems. Also, with his A64FX processor from Fujitsu based on the Armv8.2-A architecture ('Fugaku', his fourth fastest supercomputer in his latest Top500 list), HPC We have also achieved good results.

Arm CEO Rene Haas believes the rise of AI will create similar opportunities. Currently, models consume a lot of electricity, and Haas says that will increase even further in the future. Next platform.
“I spend a lot of time talking to CEOs of these companies, and this power issue is a top priority for everyone, rather than finding different ways to address it. Because all the benefits that AI is expected to bring are enormous,” Haas said. he says. “The need for computing will continue to increase, and obviously the demand for power will increase to deliver more intelligence, better models, better predictability, adding context, learning, etc. Here In the last few months, I feel like everything we're seeing in generative AI has accelerated, especially with all these complex workloads.”
Haas said Arm, along with its parent company SoftBank, is part of a recent $110 million joint US-Japan plan to fund AI research, contributing $25 million to the plan, but it is It will play a central role in containing both economic and related costs. Arm has already shown that its architecture improves data center energy efficiency by 15%. These kinds of savings can also be reflected in AI workloads, he says.
Haas notes that modern data centers currently consume about 460 terawatt-hours of electricity per year, and that number is likely to triple by 2030. Data centers currently consume about 4% of the world's electricity demand, it said. If left untreated, that percentage can rise to 25%.
It also costs money. In Stanford University's latest AI Index report, researchers wrote about the “exponential increase in the cost of training these huge models,” noting that training Google's Gemini Ultra costs about $191 million. dollars' worth of computing costs, and pointed out that OpenAI's GPT-4 cost an estimated $78 million worth. By comparison, “the original Transformer model, which introduced the architecture that underpins virtually all modern LLMs, costs about $900.”
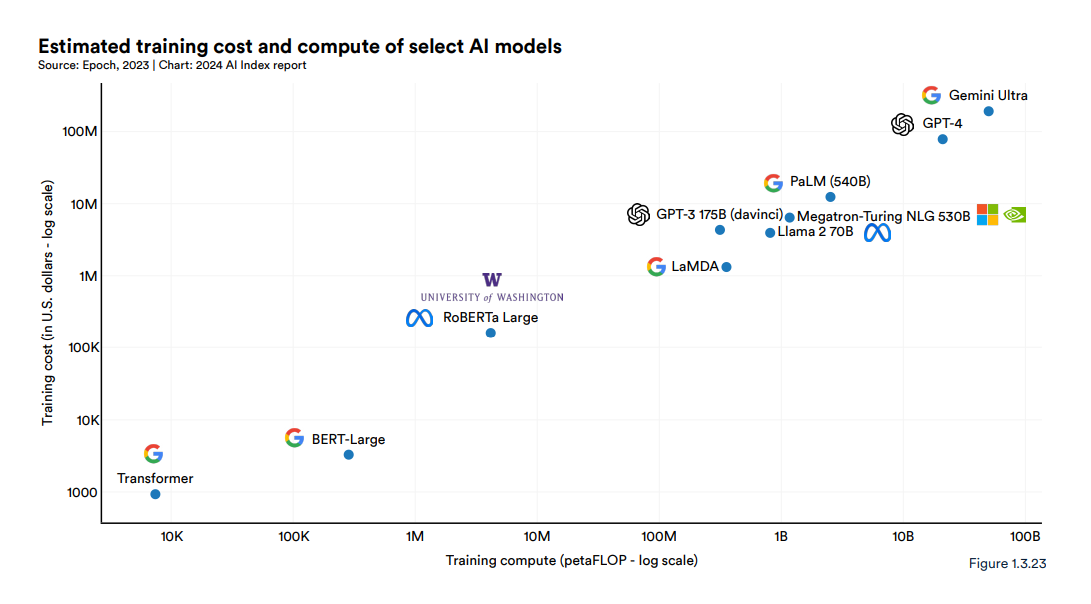

Haas says those costs will only increase. As AI companies like OpenAI and Google strive to reach artificial general intelligence (AGI), the point where AI systems can reason, think, learn, and perform as well as or better than humans, larger and more complex models You will need. Power consumption increases because more data needs to be provided.
“When you think about how sophisticated GPT-3 is compared to GPT-4, which requires 10 times more data, much larger size, longer tokens, etc., it still has the ability to do amazing things. “GPT-3 is still quite limited in terms of thinking, context, and judgment,” he says. “Models need to evolve, and at some level they need to become more sophisticated in terms of datasets. You can't really do that unless you train more and more and more. It's a virtuous cycle. You get smarter and you evolve it from the model. In order to do more research, more training will need to be performed. In the coming years, the amount of computing power required to advance this training will also be quite large. It doesn't feel like there are any big fundamental changes around the corner in terms of how things are done.”
In recent weeks, Arm, Intel, and Nvidia have announced new technologies aimed at addressing growing AI capacity demands, including pressure to run more model training and inference at the edge, where more data is being generated and stored. We have rolled out a new platform. Arm announced this month its Ethos-U85 neural processing unit (NPU), promising four times the performance and 20 percent better power efficiency than the previous generation.


On the same day, Intel announced the Gaudi 3 AI accelerator and Xeon 6 CPU, with CEO Pat Gelsinger claiming the chip's capabilities and the vendor's open systems approach will drive AI workloads the Intel way. Haas is less confident, saying, “Intel and AMD are just building a big idea of connecting standard products and Nvidia H100 accelerators that connect to Intel or AMD CPUs, so they're not going to do their own thing. It may be difficult,” he said.
Haas points out that the need to improve data center efficiency is also accelerating the trend toward custom chips, most of which are built with Arm's Neoverse architecture. These include Amazon's Graviton processor, Google Cloud's Axion, Microsoft Azure's Cobalt, and Oracle Cloud's Ampere. All of this not only drives improved performance and efficiency, but also the integration required for AI workloads.
“You can now essentially build a custom implementation of AI for your data center, configure it in almost any way you want, and get great levels of performance out of it,” he says. “These custom chips are an opportunity for us going forward.”

He points to Nvidia's AI-focused Grace Blackwell GB200 accelerator introduced last month. This includes two of his Nvidia B200 Tensor Core GPUs connected to an Arm-based Grace CPU by his 900 GB/s NVLink interconnect.
“The Grace-Blackwell is, in a sense, a custom chip, because the previous H1 100 was basically racked and connected to an X86 processor,” Haas says. “Grace-Blackwell is now highly integrated into anything that uses Arm. The level of integration that Arm allows and the customization that allows us to optimize for the types of workloads that are really the most efficient. Arm will be central to a lot of this because its architecture uses the CPU and GPU via NVLink to solve important issues around memory bandwidth. We're going to start addressing some of that, because ultimately these huge models require access to huge amounts of memory to perform inference.”
He said system-level design optimizations enabled by Arm's architecture can reduce power consumption by 25x and improve performance per GPU by 30x compared to LLM's H100 GPU. Such customization is necessary in the AI era, where the pace of innovation and adoption accelerates.
“To some extent, one of the challenges we have across the industry is that while these underlying models are getting smarter and smarter and the pace of innovation is very fast, it takes some time to build new chips. “Building a new data center takes some time, and building new power distribution capabilities takes a lot of time,” Haas said. “Being able to design chips as flexibly as possible is a huge deal. But it's happening. It's happening at an incredible pace.”