



Image credits: Haje Kamps / Midjourney
Keeping up with an industry as rapidly changing as AI is a challenge. So until AI can do it for you, here's a quick recap of recent stories in the world of machine learning, as well as notable research and experiments that we couldn't cover on our own.
Last week, Midjourney, an AI startup that builds image (and soon video) generators, made a small, blink-and-you'll-miss-it change to its terms of service related to its policy on intellectual property disputes. This primarily served to replace the tongue-in-cheek language with more legal and arguably precedent-based provisions. But the change can also be interpreted as Midjourney's confidence that AI vendors like his will prevail in legal battles with creators whose work relies on vendor training and data.


Changes to Midjourney Terms of Use.
Generative AI models like Midjourney are typically trained based on large numbers of examples (such as images and text) pulled from public websites and repositories on the web.vendor claims Fair use is a legal doctrine that allows the use of copyrighted works to create derivative works, as long as they are transformative, and protects them where model training is concerned. But not all creators agree, especially given the growing body of research showing that models can and do “regurgitate” training data.
Some vendors are taking a proactive approach, such as entering into licensing agreements with content creators and establishing “opt-out” schemes for training data sets. Some companies promise that if a customer becomes involved in a copyright lawsuit arising from a vendor's use of their GenAI tools, they will not be charged legal fees.
Mid-journey is not aggressive.
On the contrary, Midjourney has been somewhat brazen when it comes to using copyrighted works, at one point managing a list of thousands of artists, including illustrators and designers for major brands such as Hasbro and Nintendo. and the work has been or will be used for training. Mid-journey model. The study found convincing evidence that Midjourney also used TV shows and movie series to train his data, from “Toy Story'' to “Star Wars,'' “Dune'' and “The Avengers.'' is shown.
Now, there is a scenario where the court's decision ends up with an outcome similar to Midjourney. Even if the judicial system decides that fair use applies, there's nothing stopping the startup from continuing as usual, scraping and training on new and old copyrighted data.
But that seems like a risky bet.
Midjourney is currently on a roll, reportedly reaching around $200 million in revenue without using a single penny of outside investment. However, lawyers are expensive. And if it were determined that fair use did not apply in Midjourney's case, the company would be destroyed overnight.
There's no reward without risk, right?
Here are some other notable AI stories from the past few days.
AI-powered ads attract the wrong kind of attention: Creators on Instagram slammed a director who reused someone else's (much more difficult and impressive) work without credit in a commercial.
EU authorities warn of AI platforms ahead of elections: They're asking the biggest companies in the technology industry to explain their approaches to preventing election fraud.
Google Deepmind wants AI to be its partner in cooperative games: By training agents with hours of 3D game play, they can now perform simple tasks expressed in natural language.
Benchmark issues: Too many AI vendors claim that their models match or beat their competitors by some objective metric. But the metrics they use are often flawed.
AI2 gets $200 million: AI2 Incubator, a spinout from the nonprofit Allen Institute for AI, has secured a $200 million computing windfall that startups running its program can leverage to accelerate early development.
India will require government approval for AI and then rollback. The Indian government appears unable to decide what level of regulation is appropriate for the AI industry.
Anthropic launches new models: AI startup Anthropic has launched a new model family called Claude 3 that it claims is comparable to OpenAI's GPT-4. We tested the flagship model (Claude 3 Opus) and found it to be great, but it also fell short in areas like current events.
Political deepfakes: A study by the Center for Countering Digital Hate (CCDH), a UK non-profit organization, found that the amount of AI-generated disinformation on X (formerly Twitter) has increased over the past year, particularly deepfake images related to elections. This is being investigated.
OpenAI vs. mask: OpenAI says it intends to dismiss all claims made by X CEO Elon Musk in a recent lawsuit, saying the billionaire entrepreneur who helped co-found the company is behind OpenAI's development. And success that suggested it didn't actually have that much of an impact.
Review Rufus: Last month, Amazon announced that it was introducing a new AI-powered chatbot, Rufus, within the Amazon Shopping app for Android and iOS. We got early access and quickly became disappointed with the lack of things Rufus could do (and do well).
More machine learning
molecule! How do they work? AI models help us understand and predict molecular dynamics, conformation, and other aspects of the nanoscale world that would otherwise require expensive and complex methods to test. You will need. Of course it still needs to be tested, but things like AlphaFold are rapidly changing the field.
Microsoft has developed a new model called ViSNet that aims to predict so-called structure-activity relationships, the complex relationships between molecules and biological activities. This is still quite experimental and definitely aimed at researchers only, but it's always great to see difficult problems in science solved by cutting-edge technological means.

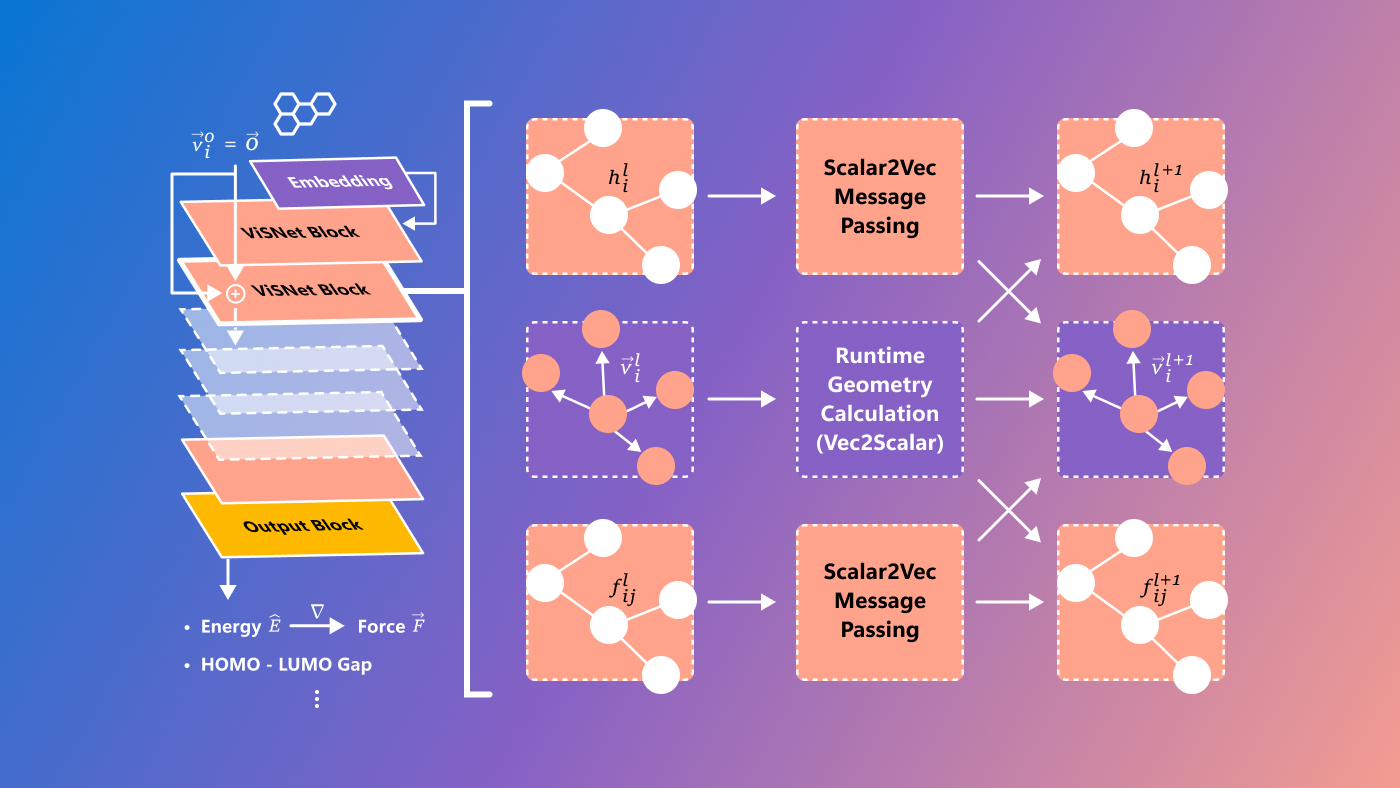
Image credits: microsoft
Researchers at the University of Manchester identify and predict variants of COVID-19 by analyzing very large genetic datasets related to coronavirus evolution, rather than from pure structures like ViSNet. We are paying particular attention to.
“The unprecedented amount of genetic data generated during the pandemic requires improved methods to thoroughly analyze it,” said lead researcher Thomas House. “Our analysis serves as a proof of concept and shows the potential for machine learning techniques to be used as a warning tool for early detection of emerging major variants,” said his colleague Roberto Cahuantzi. ” he added.
AI can also design molecules, and many researchers have signed on to initiatives calling for safety and ethics in this field. However, David Baker, one of the world's leading computational biophysicists, says that “the potential benefits of protein design far outweigh the risks at this point.” As the designer of AI Protein Designer, he will do Say. But we must still be wary of regulations that miss the mark and impede legitimate research while allowing freedom for bad actors.
Atmospheric scientists at the University of Washington made an interesting claim based on an AI analysis of 25 years of satellite imagery over Turkmenistan. Fundamentally, the commonly accepted understanding that post-Soviet economic turmoil led to a decline in emissions may not be true; in fact, the opposite may be happening.

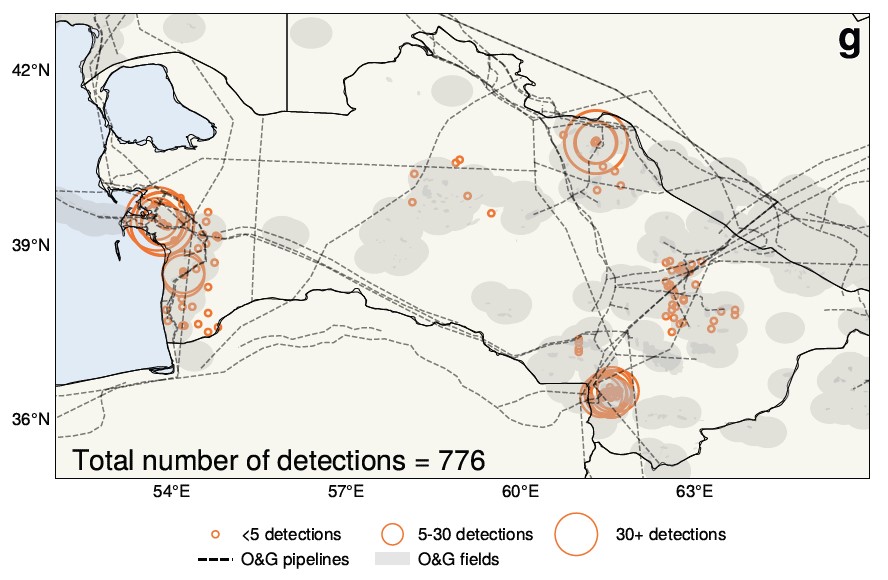
AI helped discover and measure the methane leak shown here.
“The collapse of the Soviet Union surprisingly appears to have increased methane emissions,” said Alex Turner, a professor at Wisconsin State University. The large datasets and lack of time to comb through them made this topic a natural target for AI, resulting in this unexpected reversal.
Large-scale language models are primarily trained with English source data, but this can impact more than their ability to use other languages. EPFL researchers investigated LlaMa-2's “latent language” and found that even when translating between French and Chinese, the model appears to revert to English internally. However, researchers suggest that this is not just a lazy translation process; in fact, the model structures its entire conceptual latent space around English concepts and expressions. Does it matter? probably. You need to diversify your dataset anyway.